
Using Multimodal AI Models For Your Applications
In this third and final part of a three-part series, we’re taking a more streamlined approach to an application that supports vision-language (VLM) and text-to-speech (TTS).
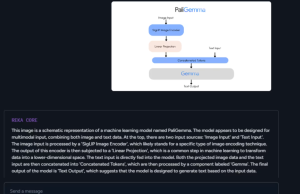
In this third and final part of a three-part series, we’re taking a more streamlined approach to an application that supports vision-language (VLM) and text-to-speech (TTS).
